本文共 2746 字,大约阅读时间需要 9 分钟。
笔记整理 | 孙磊,天津大学硕士。

动机
RDF形式的语义网的繁荣对高效、可伸缩以及分布式的存储和高可用和容错并行策略都有着要求。RDF数据的飞速增长提升了在分布式数据管理系统上高效划分策略的需求来提升SPARQL查询性能。
亮点
本文提出了新的用于RDF的关系分割架构Property Table Partitioning(PTP),它将现有的属性表基于独有的属性()划分成多个表来最小化输入数据和join操作。本文将介绍一个基于Spark,使用SQL在PTP架构上执行SPARQL查询的分布式RDF数据管理系统S3QLRDF
方法
S3QLRDF(SPARQL to Spark SQL for RDF)是一个基于Hadoop和Spark的针对大规模RDF数据的分布式SPARQL查询处理器。它将SPARQL编译成SQL并根据RDF数据分割架构PTP,使用了Spark的关系接口来进行查询执行。
l属性表划分
Modified Property Table是传统PT的一个修改版本,其中多值属性被使用如Array的嵌套数据结构存储在一个格子内。本文使用N-Triples格式的数据,首先创建一个TT(Triple Table),然后创建如下格式的PT(Property Table),其中n是RDF
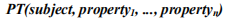
数据集中独有属性的总数。这里每个RDF主语都被存储在主语列,它们的宾语值存储在对应的属性列中。下一步,将Modified Property Table基于独有属性划分成多个表。每个PTP表根据划分情况只包含有特殊值的主语,然后使用特殊属性作为划分的表名。下面的表2就是由表1获得的划分后的属性表。
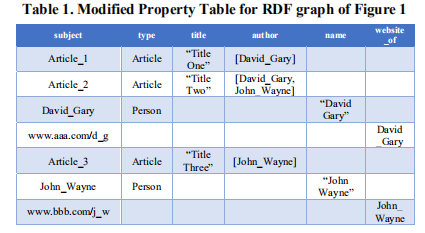
本文还保存了一个统计文件来存储每个PTP表的实际大小和多值属性的名称,这将在查询生成时用到。
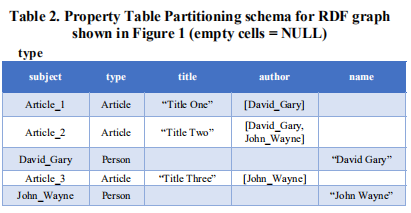
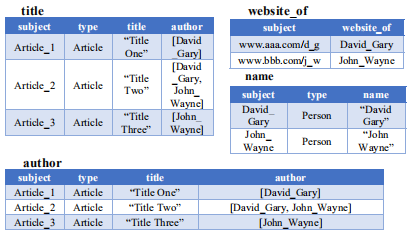
(1)查询处理
为了生成对应于SPARQL查询的Spark SQL表达式,本文了使用Flex,Bison和C++14实现了一个查询编译器。
BGP查询时SPARQL查询的核心,本文主要关注BGP分块。一个triple group(tg)由BGP中有相同主语的triple pattern构成。
考虑以下BGP

可被分成三个triple group,然后对每个triple group中固定值的数量进行计数,其中,tg1->1,tg2->1,tg3->0。这里每个triple group都可以不使用join来通过子查询来回答,三元组中的固定值都作为WHERE语句中的条件。主语和宾语基于它们在三元组中的位置被映射成变量。
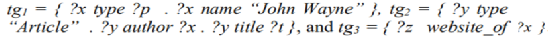
因为系统知道PTP表的实际大小,对于一个triple group,它可以选择有最少三元组的表。例如,tg1有两个独有属性type和name,所以有两个候选表可用。从统计文件中可知,type表的三元组数量是5而name表是2,所以系统将为tg1选择name表。然后,系统将基于固定值的数量和选择的表大小来安排执行顺序。有最多固定值的triple group将有最高的执行优先级。当固定值数量相同时,有最少三元组的表将有更高的优先级。例如,tg1和tg2都有最多的固定值,但tg1选择的表比tg2选择的表有更少的三元组,所以tg1将有更高的执行优先级。所以最后的执行顺序是tg1->tg2->tg3。
全部的SPARQL翻译过程如下:
对应于tg1的子查询sq1为

由统计文件可知,author是一个多值属性。因此author列将被平整,对应于tg
2的第二个子查询sq2为:

对应于tg3的第三个子查询sq3为:
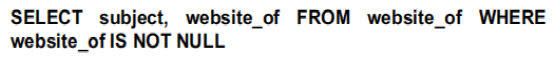
在得到最后的执行顺序以及每个triple group的变量映射后,我们得到了对应于bgp的sql查询:

因此,输入的SPARQL查询通过将操作符映射成对应的Spark SQL关键词被翻译成了对应的Spark SQL查询。SPARQL中的Filter表达式被映射成Spark SQL中的对应的WHERE语句中的Spark SQL陈述中的条件。OPTIONAL模式被映射到LEFTOUTER JOIN,UNION,LIMIT,ORDER BY,和DISTINCT可以直接被映射成Spark SQL中的对应语句。
理论分析
实验
作者使用了两个合成的数据集LUBM和WatDiv。LUBM是一个在2005年提出的数据生成器,被设计用来测试语义网存储的推理能力。LUBM提供了14个预先定义的测试查询,但是这些查询中大多数的结构都很简单并且都很相似。Waterloo大学在2014年发布了WatDiv,它被设计用来覆盖架构和数据驱动的4种不同类型的SPARQL查询,线性、星型、雪花和复杂型。
本文将S3QLRDF的原型与4种其他开源的基于Hadoop的系统:CliqueSquare、S2RDF、SPARQLGX和Rya进行对比。
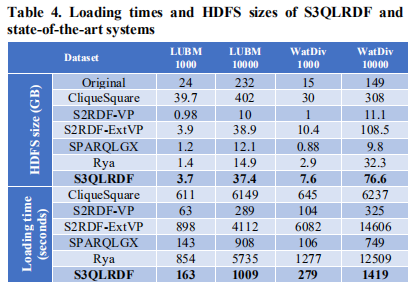
图4列出了存储大小和数据加载时间。在数据加载阶段,本文将所有的URI使用对应的名称空间的前缀替代并且移除数据类型信息将其转换成原始类型来解析数据。
本文将S3QLRDF与其他系统从如下方面进行性能方面的比较:预处理(加载)时间,存储大小,查询执行时间。所有测量都测试四轮取平均值。S3QLRDF有两布加载过程,第一步创建属性表,第二步创建PTP表。因为Spark SQL有cacheTable功能将表缓存在内存中,对于缓存和不缓存PTP表的情况分别测量执行情况。
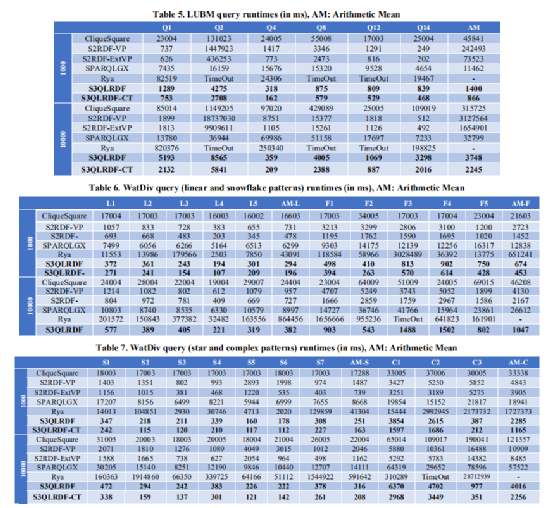
图5中,可以观察到S3QLRDF在LUBM上的表现好于所有其他系统至多一个量级。Q1和Q4是最有选择性的查询,返回很少的结果,S3QLRDF能在5200ms或更少的时间回答。这些查询是星型模式,S3QLRDF能使用PTP表高效地回答。对于最没有选择性地Q14,S3QLRDF也表现地比其他系统更好。Q2、Q8和Q12是复杂模式的查询,其中Q8和Q12产生的结果不随着数据集的大小增加而变化。
图6和7展示了不同系统在WatDiv数据集上的表现对比,S3QLRDF和S3QLRDF-CT的表现再次在所有类型查询中随着数据集大小增加有很好的表现。
总结
本文提出了一个基于PTP存储架构和Spark的分布式RDF存储和SPARQL查询系统S3QLRDF。S3QLRDF通过将SPARQL编译成SQL使用Spark SQL的接口来执行查询。本文通过在Hadoop集群上使用不同数据集和多种查询类型,与其他系统进行性能评价比较。本文提出的S3QLRDF系统对于所有查询类型的表现达到了分布式SPARQL查询处理器的最佳。
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenK
转载地址:http://yesli.baihongyu.com/